


语音交互技术原理
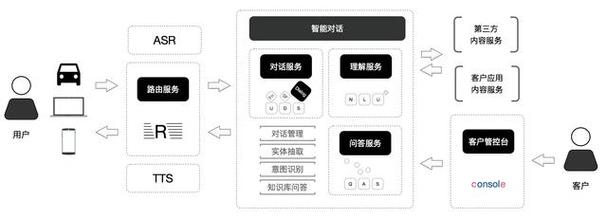
语音交互系统通常由语音识别(ASR
)、自然语言处理(NLP)和语音合成(TTS)三大核心技术组成。语音识别负责将人类语音转换为文本,自然语言处理理解文本含义并生成响应,语音合成则将文本转换为自然语音输出。近年来,随着深度学习技术的发展,端到端的语音交互系统取得了显著进步,识别准确率在特定场景下已超过人类水平。
1. 语音识别技术突破
传统语音识别系统采用GMM-HMM模型,而现代系统普遍使用深度神经网络(DNN)和长短时记忆网络(LSTM)。最新的Transformer架构在语音识别任务中表现出色,结合自注意力机制,能够更好地处理长时依赖问题。2023年,Whisper等开源模型的出现,进一步推动了语音识别技术的普及。
2. 自然语言理解进展
自然语言处理是语音交互中最具挑战性的环节。预训练语言模型如BERT、GPT系列的出现,大幅提升了机器对自然语言的理解能力。特别是大语言模型(LLM)的兴起,使得语音助手能够进行更自然、更智能的对话。多模态大模型进一步整合了语音、文本、图像等多种信息,为更丰富的交互体验奠定了基础。
语音交互应用场景
语音交互技术已广泛应用于消费电子、智能家居、汽车、医疗、教育等多个领域。不同场景对语音交互的需求和技术要求各不相同,形成了多样化的应用模式。
1. 智能家居场景
智能音箱是语音交互在消费领域的典型应用。Amazon Echo、Google Home、天猫精灵等产品通过语音控制家电、查询信息、播放音乐等功能,改变了家庭交互方式。据统计,2023年全球智能音箱出货量达到2.5亿台,语音助手已成为智能家居的核心控制入口。
2. 车载语音系统
车载语音交互系统能够在不分散驾驶员注意力的情况下完成导航、娱乐、通讯等操作,大幅提升驾驶安全性。现代高端车型普遍配备多麦克风阵列和降噪算法,即使在高速行驶的嘈杂环境中也能实现高精度语音识别。特斯拉、蔚来等电动车厂商正在开发基于大模型的下一代车载语音助手。
语音交互发展趋势
随着技术进步和应用深入,语音交互正朝着更自然、更智能、更个性化的方向发展。以下几个趋势值得关注:
常见问题解答
Q1: 语音交互系统的响应速度如何提升?
A1: 通过模型压缩、硬件加速、边缘计算等技术可以显著提升响应速度。现代语音交互系统端到端延迟可控制在500毫秒以内,部分场景下达到实时交互水平。
Q2: 语音识别在嘈杂环境中的准确率如何保证?
A2: 采用波束成形、深度降噪、回声消除等技术可有效提升嘈杂环境下的识别率。多麦克风阵列和自适应算法能够动态调整参数,适应不同噪声环境。
Q3: 语音交互系统如何保护用户隐私?
A3: 主流方案包括本地处理敏感信息、数据加密传输、用户授权管理等。部分设备还提供物理开关,允许用户完全关闭麦克风功能。
语音交互技术正在重塑人机交互方式,其发展前景广阔但挑战也不少。随着技术进步和应用场景拓展,语音交互将变得更加智能、自然和无缝,最终实现"说话即操作"的理想交互体验。企业需要持续投入研发,解决隐私、安全、多语言支持等关键问题,推动语音交互技术向更高水平发展。