


一、高可用集群的基本概念与核心价值
高可用集群(High Availability Cluster)是指通过软件和硬件技术将多台服务器组合成统一资源池,当某个节点发生故障时,集群系统能够自动检测并将服务迁移至健康节点。这种架构通过消除单点故障,显著提升系统可靠性,典型可用性可达99.99%(年停机时间不超过52分钟)。在金融交易、医疗信息系统、电信运营等关键领域,高可用集群已成为标准配置。其核心价值体现在三个方面:是通过冗余设计预防硬件故障;是利用负载均衡优化资源利用率;最重要的是实现故障自动转移(Failover),确保业务无感知切换。
二、主流高可用集群架构解析
现代高可用集群主要采用三种典型架构模式。主动-被动(Active-Passive)架构中,备用节点处于待命状态,仅在主节点故障时接管服务,适合对数据一致性要求严格的场景。主动-主动(Active-Active)架构允许所有节点同时处理请求,通过负载均衡器分发流量,最大化利用硬件资源,但需要解决数据同步难题。多主架构则常见于分布式数据库系统,各节点均可读写,采用Paxos/Raft等共识算法保证数据一致性。具体架构选择需考虑业务连续性要求、预算限制以及技术栈兼容性等因素。,Oracle RAC采用共享存储的主动-主动架构,而Microsoft Failover Cluster则多采用主动-被动模式。
三、高可用集群的关键技术组件
集群节点间通过周期性的心跳信号(Heartbeat)相互监测状态,通常采用多路径检测(如以太网+串口)避免误判。现代系统普遍使用基于UDP的多播心跳,检测延迟可控制在毫秒级。当连续丢失3-5个心跳包时触发故障判定,比传统轮询方式更高效。
为防止"脑裂"(Split-Brain)现象,集群需要可靠的仲裁机制。STONITH(Shoot The Other Node In The Head)通过硬件管理接口强制隔离故障节点,配合Quorum Disk或仲裁节点实现多数决判断。云环境下可借助第三方仲裁服务如AWS的Termination Protection。
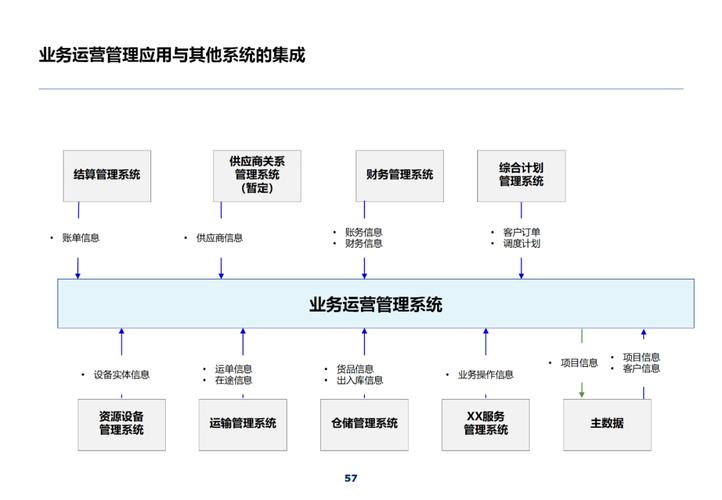
四、典型高可用集群解决方案对比
Linux生态中,Pacemaker+Corosync组合提供开源高可用解决方案,支持复杂的资源约束规则和跨节点依赖管理。Windows Server的Failover Clustering深度集成Hyper-V和Storage Spaces,简化了虚拟化环境部署。商用方案如Veritas Cluster Server在异构环境支持方面表现突出,而Kubernetes通过Pod反亲和性、健康探针等机制实现了容器级高可用。存储层面,Ceph和GlusterFS等分布式存储系统通过数据多副本保障可用性,与计算层高可用集群形成互补。
五、高可用集群实施的最佳实践
成功的集群部署始于严谨的规划设计阶段。建议采用"N+1"冗余模型,即满足峰值负载所需节点数加备用节点。网络配置需实现多网卡绑定(如LACP)和VLAN隔离,存储建议选用支持多路径IO的SAN或高性能NAS。测试环节必须包含计划内故障转移演练(如手动关闭节点)和混沌工程测试(随机杀死进程)。监控系统应覆盖集群状态、资源利用率、故障切换耗时等关键指标,并与现有运维平台集成。文档方面需详细记录回切流程、故障排查手册和供应商支持联系人。
高可用集群配置是平衡成本与可靠性的系统工程。随着云原生技术的发展,混合云高可用、服务网格容错等新范式正在重塑传统集群架构。企业应根据业务实际需求选择合适方案,并通过持续测试优化确保故障恢复能力。记住,真正的高可用不仅是技术实现,更是贯穿设计、实施、运维全生命周期的质量承诺。常见问题解答:
基础高可用至少需要2个节点,但生产环境建议3节点起步以避免脑裂风险。关键业务系统应采用跨机房的多活部署。
取决于实现方式,采用内存热备和TCP会话保持技术的集群可实现毫秒级切换,对短连接业务可能完全无感知。
应定期进行"断电测试"模拟节点故障,测量MTTR(平均恢复时间),并验证数据一致性。云环境可利用Chaos Monkey等工具。
需要,VMware vSphere HA等方案解决的是宿主机级故障,而应用层集群处理的是guest OS内部的服务高可用。
心跳检测、状态同步等操作通常消耗<5%的系统资源,但写密集型应用在同步复制模式下可能有20-30%的性能损耗。