


数据湖的基本概念与特征
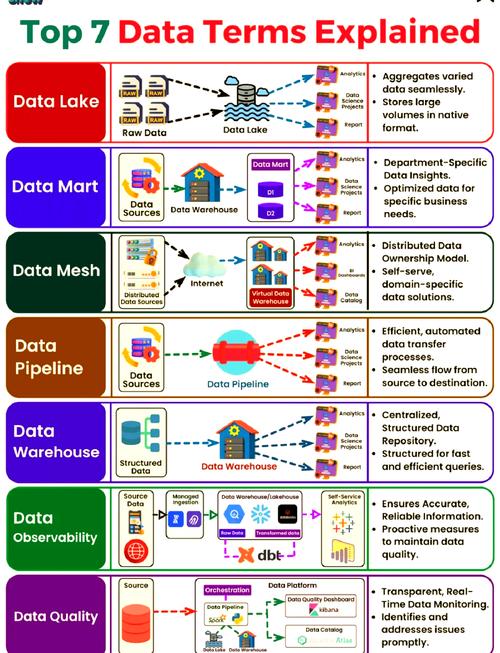
数据湖是一种集中式存储库,允许以原生格式存储任意规模的结构化、半结构化和非结构化数据。与数据仓库相比,数据湖最显著的特征是其"先存储后处理"的模式,这种模式极大地提高了数据采集和存储的效率。数据湖采用扁平化的架构设计,通过元数据管理和数据目录技术,使得用户可以按需访问和处理数据,而不需要预先定义严格的数据模式。
数据湖与传统数据仓库的对比
传统数据仓库采用ETL(抽取-转换-加载)流程,要求数据在入库前就必须完成清洗和结构化处理。而数据湖则采用ELT(抽取-加载-转换)模式,原始数据可以直接存入湖中,待需要分析时再进行转换。这种差异使得数据湖能够更快地接收新数据源,同时保留数据的原始状态,为后续各种分析需求提供更大的灵活性。
数据湖的技术架构与核心组件
存储层设计
现代数据湖通常构建在分布式文件系统(如HDFS)或对象存储(如Amazon S3)之上,这些底层存储系统提供了高扩展性和高可用性。存储层设计需要考虑数据分区策略、压缩格式选择以及生命周期管理等因素,以优化存储成本和查询性能。典型的数据湖采用分区存储策略,可以按照时间、业务域或其他逻辑维度组织数据。
数据处理与分析层
数据处理层是数据湖架构中的核心,通常包含批处理和流处理两种能力。Spark、Flink等计算框架可以高效处理湖中数据,而Presto、Athena等查询引擎则提供交互式分析能力。数据湖还整合了机器学习框架和高级分析工具,支持从数据中发现更深层次的业务洞察。
数据湖的实施策略与最佳实践
成功实施数据湖需要周密的规划和执行。需要明确业务目标和用例,避免建设"数据沼泽"。要建立完善的数据治理框架,包括元数据管理、数据质量监控和访问控制等机制。在技术选型方面,企业可以根据自身需求选择商业解决方案(如Azure Data Lake)或开源技术栈(如Delta Lake、Iceberg)。
数据湖作为现代数据架构的重要组成部分,正在重塑企业的数据管理方式。通过合理规划和实施,数据湖可以帮助企业释放数据价值,加速数字化转型。未来,随着技术的不断演进,数据湖将与数据仓库、数据网格等架构进一步融合,形成更加灵活高效的数据生态系统。
常见问题解答
Q:数据湖适合哪些类型的企业?
A:数据湖特别适合数据量大、来源多样且分析需求多变的企业。互联网公司、金融机构、电信运营商等数据密集型行业都能从数据湖中获益。
Q:如何避免数据湖变成"数据沼泽"?
A:关键在于建立完善的数据治理机制,包括元数据管理、数据目录、质量监控和访问控制。同时要确保每个进入数据湖的数据都有明确的业务用途。
Q:数据湖与数据仓库应该如何共存?
A:最佳实践是构建"湖仓一体"架构,数据湖用于原始数据存储和探索性分析,数据仓库则服务于需要高性能和严格治理的报表和BI场景。