


监控告警的核心原理与技术架构
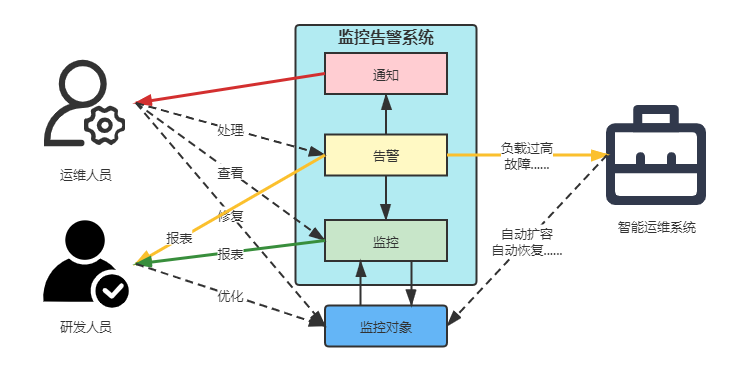
监控告警系统的基本工作原理是通过数据采集、指标计算、阈值判断和通知触发四个关键环节实现异常检测。现代监控告警系统通常采用分布式架构设计,包含数据采集层、数据处理层、存储层、告警引擎和通知渠道等核心组件。
数据采集层的技术选型
数据采集是监控告警的基础,常见的数据采集方式包括Agent采集、SNMP协议、API调用和日志解析等。Prometheus的Exporter、Telegraf等开源采集工具支持多种数据源,能够满足不同场景的监控需求。采集频率通常设置在15秒到1分钟之间,需要根据业务敏感度和系统负载进行合理配置。
数据处理与存储方案
采集到的监控数据需要经过清洗、聚合和标准化处理后存储到时序数据库中。InfluxDB、Prometheus TSDB和Elasticsearch是当前主流的时序数据存储方案,支持高效的数据写入和查询。对于大规模监控场景,需要考虑数据分片和长期存储策略,避免存储成本过高。
告警规则配置与告警分级策略
合理的告警规则配置是避免告警风暴的关键。告警规则通常基于阈值判断、同比环比分析和机器学习异常检测等方法。企业应根据业务重要性设置多级告警策略,如P0-P4五个级别,并配置不同的告警通知方式和响应时效要求。
告警收敛与降噪技术
告警收敛技术可以有效减少重复告警和无效告警,常见的方法包括告警聚合、依赖关系分析和根因定位等。开源的Alertmanager和商业的PagerDuty都提供了强大的告警收敛功能,能够根据标签、时间窗口等条件对告警进行智能合并。
告警通知渠道整合
现代监控告警系统支持多种通知渠道,包括邮件、短信、电话、企业微信、钉钉和Slack等。建议配置多通道冗余通知机制,确保关键告警能够及时送达。同时需要建立通知反馈机制,确认告警接收和处理状态。
企业级监控告警系统实施指南
构建企业级监控告警系统需要遵循标准化、自动化和智能化的原则。建议采用分阶段实施策略,先从基础设施监控开始,逐步扩展到应用性能监控和业务指标监控。
监控告警系统的运维同样重要,需要定期检查告警规则的有效性,清理过期告警,优化告警阈值。同时要建立告警响应SOP和值班制度,确保告警能够得到及时处理。
通过本文的介绍,相信您已经对监控告警系统有了全面的了解。一个设计良好的监控告警系统能够显著提升运维效率,降低系统风险,是企业数字化转型的重要保障。建议根据自身业务特点和技术栈,选择合适的监控告警方案,构建符合企业需求的监控告警体系。
常见问题解答
Q1:如何避免监控告警系统的误报问题?
A1:可以通过设置合理的告警阈值、采用动态基线算法、配置告警静默期等方式减少误报。同时建议定期review历史告警,优化告警规则。
Q2:监控告警系统应该监控哪些关键指标?
A2:关键指标包括系统资源使用率(CPU、内存、磁盘
)、服务可用性(响应时间、错误率
)、业务核心指标(交易量、转化率)等。具体需要根据业务特点确定。
Q3:如何实现监控告警系统的自动化响应?
A3:可以通过集成自动化运维平台,针对特定告警触发预定义的修复脚本或工作流。自动扩容、服务重启等操作,实现部分故障的自愈。