


数据血缘的核心价值
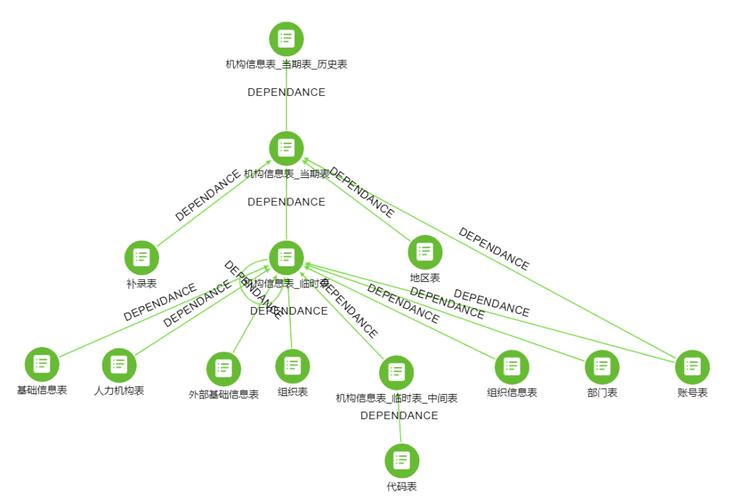
数据血缘的核心价值在于它能够提供数据的透明度和可追溯性。在数据治理框架中,数据血缘帮助企业回答"数据从哪里来"、"经过了哪些处理"、"最终用在哪里"等关键问题。这种透明度对于数据质量管控、合规审计、影响分析和问题排查都至关重要。
提升数据可信度
通过数据血缘,用户可以清楚地了解数据的来源和处理过程,从而评估数据的可信度和适用性。,在金融行业,监管机构要求金融机构能够证明其报告数据的准确性和完整性,数据血缘为此提供了必要的证据链。
加速问题诊断
当数据出现异常或错误时,数据血缘可以快速定位问题的根源。通过追踪数据的流动路径,技术人员可以迅速确定是哪个环节的处理逻辑出了问题,或是哪个数据源提供了错误数据,大大缩短了故障排查时间。
数据血缘的实现方法
实现数据血缘需要结合技术工具和管理流程。从技术角度看,数据血缘的实现通常包括元数据采集、关系分析和可视化展示三个主要步骤。
元数据采集技术
元数据是描述数据的数据,是构建数据血缘的基础。现代数据平台通常采用自动化的元数据采集工具,通过解析SQL脚本、ETL作业、BI报表等数据资产,提取其中的数据转换关系和依赖关系。一些先进的解决方案还能捕获运行时数据流,提供更真实的数据移动轨迹。
血缘关系分析
采集到元数据后,需要通过算法分析数据实体之间的关系。这包括识别直接的血缘关系(如父子表关系)和间接的依赖关系(如通过中间表的关联)。图数据库技术在此环节发挥重要作用,能够高效存储和查询复杂的数据关系网络。
数据血缘的应用场景
数据血缘在各行业都有广泛应用,特别是在金融、医疗、电信等数据密集型行业。以下是几个典型的应用场景:
数据血缘的常见问题解答
1. 数据血缘与数据谱系有什么区别?
数据血缘(Data Lineage)侧重于数据的流动和转换过程,强调数据的"来龙去脉";而数据谱系(Data Provenance)更关注数据的起源和出处,强调数据的"血统"和来源可信度。两者密切相关但侧重点不同。
2. 如何保证数据血缘的准确性?
保证数据血缘准确性需要多管齐下:采用自动化工具减少人工错误;建立元数据管理规范;定期进行血缘验证;将血缘维护纳入数据开发流程。结合数据质量监控工具可以及时发现血缘不一致问题。
3. 数据血缘分析对性能有什么影响?
在大规模数据环境下,血缘分析确实可能带来性能挑战。优化方法包括:采用增量式血缘采集;使用图数据库存储血缘关系;实施分级血缘管理(区分核心数据和非核心数据);对血缘查询进行缓存等。
数据血缘作为数据治理的重要工具,正在成为企业数据战略的基础设施。随着数据复杂度的增加和监管要求的提高,构建全面、准确、实时的数据血缘系统将成为企业数据能力的关键差异化因素。通过有效实施数据血缘管理,企业能够提高数据可信度,降低合规风险,加速数据分析,最终实现数据价值的最大化。