


ETL流程的基本概念
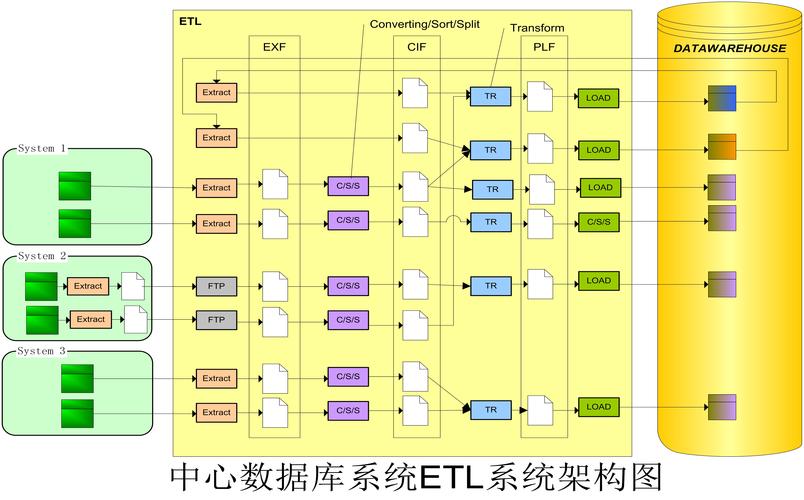
ETL流程是数据集成领域的基础技术,它包含三个主要阶段:数据抽取(Extract
)、数据转换(Transform)和数据加载(Load)。在数据抽取阶段,系统会从各种异构数据源(如关系型数据库、NoSQL数据库、平面文件、API等)中提取所需数据。数据转换阶段则负责对原始数据进行清洗、标准化、聚合和丰富等操作,确保数据质量和一致性。在数据加载阶段,经过处理的数据会被加载到目标数据仓库或数据湖中,供分析使用。
ETL流程的详细实施步骤
1. 数据抽取阶段的关键技术
数据抽取是ETL流程的第一步,也是整个流程的基础。在这个阶段,需要考虑多种技术方案:全量抽取适用于小规模数据集,而增量抽取则更适合处理大数据量,通过识别新增或修改的记录来提高效率。变更数据捕获(CDC)技术可以实时跟踪源系统的数据变化,最小化ETL处理窗口。同时,连接池技术和并行抽取策略能够显著提升数据抽取的性能。
2. 数据转换阶段的核心处理
数据转换是ETL流程中最复杂的环节,涉及多种数据处理技术:数据清洗包括处理缺失值、纠正错误数据和消除重复记录;数据标准化确保不同来源的数据采用统一的格式和单位;数据丰富通过添加计算字段或关联外部数据来增强数据价值;数据聚合则对明细数据进行汇总计算,生成分析所需的聚合指标。数据验证规则和异常处理机制也是确保数据质量的关键组件。
ETL工具与平台选择
市场上有多种ETL工具可供选择,从传统的Informatica PowerCenter、IBM DataStage到开源的Talend Open Studio、Apache NiFi,以及云原生的AWS Glue、Azure Data Factory等。选择ETL工具时需要考虑多个因素:数据量大小和复杂度、实时性要求、团队技能水平、预算限制以及与企业现有技术栈的兼容性。现代ETL平台越来越倾向于提供可视化开发界面、预构建连接器和弹性扩展能力,大大降低了ETL实施的难度。
ETL流程优化与最佳实践
优化ETL流程是确保数据处理效率的关键。分区处理技术可以将大数据集分割成小块并行处理;内存计算显著提高转换速度;适当的索引策略能加速数据加载;增量处理代替全量刷新可减少资源消耗。监控和日志记录机制对于及时发现和解决问题至关重要。实施数据血缘跟踪和影响分析功能,可以帮助理解数据的来源和转换过程,增强数据可信度。
常见问题解答
Q1: ETL和ELT有什么区别?
ETL是传统的数据处理模式,数据在加载前完成转换;而ELT(Extract-Load-Transform)则是现代大数据环境下的变体,先将原始数据加载到目标系统,再利用目标系统的计算能力进行转换。
Q2: 如何选择批处理还是实时ETL?
批处理适合对延迟不敏感的分析场景,实现简单且资源利用率高;实时ETL则适用于需要即时数据分析的业务场景,但实现复杂且成本较高。
Q3: ETL流程中如何确保数据质量?
可以通过实施数据验证规则、异常处理机制、数据质量监控仪表盘,以及建立数据质量评分体系来确保ETL流程中的数据质量。
Q4: 云环境下的ETL有什么特殊考虑?
云环境下的ETL需要考虑数据安全传输、跨区域数据移动成本、弹性扩展能力以及与云原生服务的集成等因素。
ETL流程作为数据管理的核心环节,其设计和实施质量直接影响数据分析的准确性和时效性。随着数据量的爆炸式增长和数据类型的多样化,ETL技术也在不断演进,从传统的批处理向实时流处理扩展,从集中式架构向分布式架构转变。掌握ETL流程的原理和实践,对于构建高效可靠的数据管道、释放数据价值具有重要意义。通过本文介绍的ETL流程知识、实施方法和优化技巧,您将能够设计出满足业务需求的高性能ETL解决方案。